
PantherFlow is Panther’s piped query language that supports filtering, transforming, and aggregating data in a way that should feel familiar to those who have experience with other pipelined languages. In our last blog, we talked about why we created PantherFlow, including how it improves search with an intuitive, logical syntax that retains the power of SQL, without inheriting its complexities.
In this blog, we’ll deep dive into PantherFlow’s syntax and features, showing you how to write PantherFlow queries and how it integrates into Panther’s search experience.
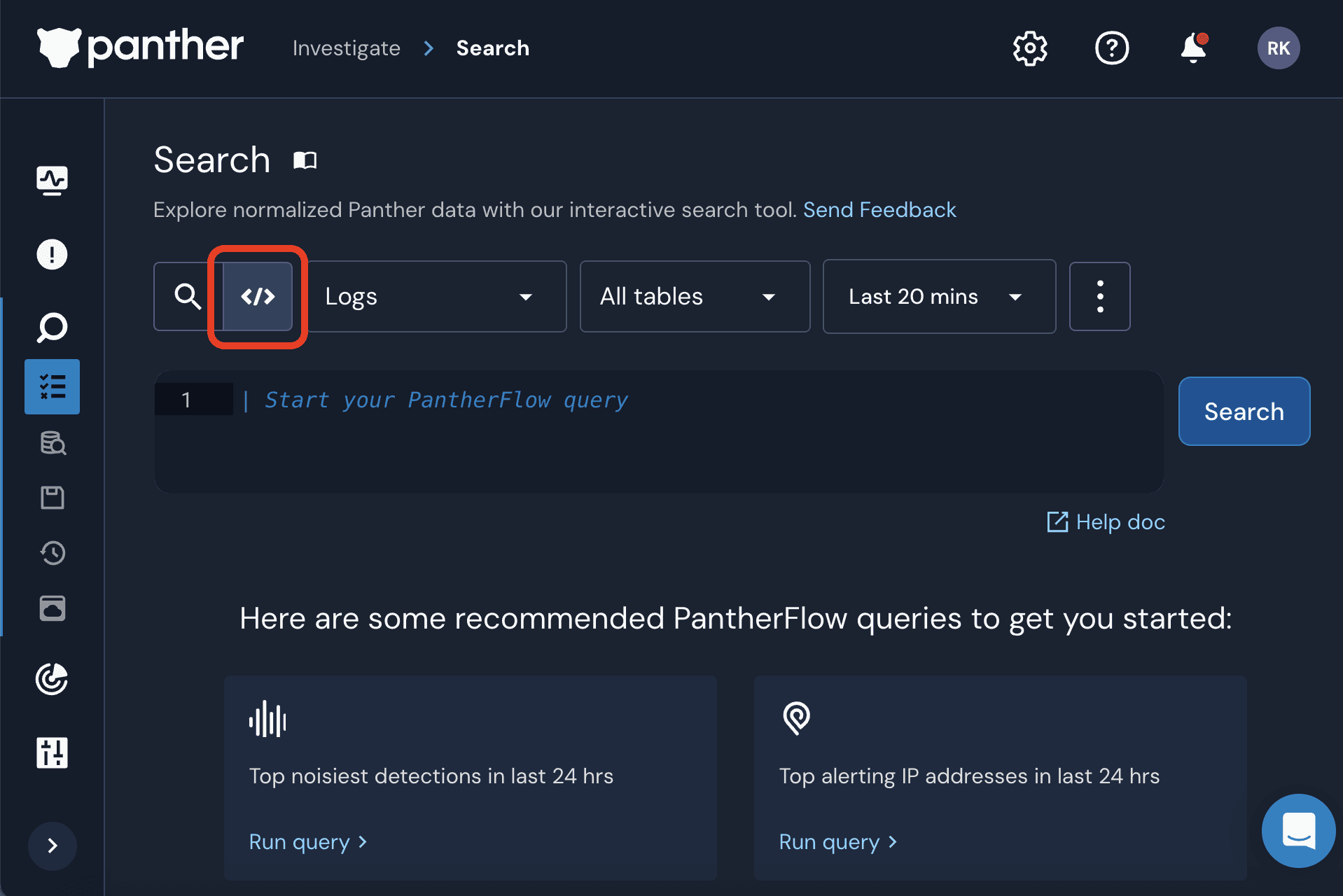
Fully Integrated into Search
In Panther’s Search interface, you can switch into PantherFlow mode by selecting the toggle button </>, as shown in the following image. In this mode, you type queries in PantherFlow while still retaining all of the features of the existing Search interface, including:
Data is returned in time order but can be overridden with PantherFlow’s
sortoperatorLimits are handled transparently, although the PantherFlow’s
limitoperator is available for extra controlSummary statistics of the “Top N” values of a given field can be generated
Additional filter criteria can be added to your PantherFlow query with the click of a button
The Database, Table, and Time Range dropdown fields can be used to select your input data, or you can override these values directly in the PantherFlow query
It Starts with a Table
A table name is a valid query. Subsequent filters, transforms, or joins are added on new lines starting with the pipe | symbol. Comments begin with //. Read more about PantherFlow statements in the docs.
Expressive Filtering
The where operator lets you write complex expressions. You can use typical boolean logic (and, or, not) to combine expressions, typical comparisons (== , < , <=, >, >= and !=, and in) and a growing set of function calls to produce complex queries.
Transform your Data
You can transform your data with extend and project. Use the extend operator to add fields based on any expression or function call you wish. Updates to your data can be referred to later on in the query:
Similarly, the project operator adds new fields after dropping all existing fields:
Aggregate
No self respecting query language would be complete without the ability to aggregate data, and PantherFlow is no different. The summarize operator lets you aggregate data:
You can rename fields, use arbitrary expressions and, of course, you can refer to added fields later in the query:
Data Types that Are a Superset of JSON
PantherFlow’s data types are a superset of JSON, so anything that is valid JSON can be used in PantherFlow as an expression. This means PantherFlow has support for both arrays [1, "foo", 2.3] and objects {"a": 1, "b": 2}.
Data types are evaluated as expressions so they can contain function calls and refer to fields in the query:
Multi-Table Queries
As a result of PantherFlow’s semi-structured nature, you can search across multiple tables with the union operator, even when they contain different columns. No special handling is needed. Data that does not exist in a table is null.
First Class Time Intervals
Time intervals are treated as first class types, for example: 1d (one day), 15m (15 minutes), 60s (60 seconds), etc. Time intervals can be passed to functions or computed arithmetically.
Deeply nested object paths
It is straightforward to refer to deeply nested values and arrays. Object attributes can be accessed with a period (.). Square brackets ([]) can be used to access an attribute as a string or array index.
Named Subqueries
You can name queries with the let keyword and treat them like a first class table. This incurs zero cost overhead: only subqueries that are needed are computed.
Null Handling
The way that SQL handles NULL is confusing, and arguably requires a lecture in three-valued logic. In comparison, PantherFlow treats null as a value so comparisons like foo == null and foo != null do exactly what you think. There is no IS keyword in PantherFlow.
Join Support
PantherFlow supports joins with the join operator, including the ability to join on a subquery:
Text Searching
If you’ve ever had to search for a particular string in your logs but don’t know what field it is in, we feel your pain. Arbitrary strings can be found anywhere in your data with the search operator:
You can combine strings with boolean logic, and wildcards are supported too:
Inject Data into your Query
You can inject data into a query with the datatable operator. And because JSON is valid PantherFlow, you can copy and paste JSON directly from the source.
You can also use expressions within the datatable:
You can combine the union operator with datatable to inject values into your query results:
Unicode Support!
And finally, a bit of a fun feature, we have full support for unicode in strings.
Forward-looking
In designing PantherFlow we emphasized simplicity, ease of use, and productivity. Whether it’s the ability to search for a known bad indicator string anywhere in your logs, pivot and enrich with join, combine multiple tables into a single query, or generate informative summaries, we’ve created PantherFlow to be a search language that you actually enjoy using.
We think this set of features is already compelling but we are continuing to improve and invest in PantherFlow. One such feature is our upcoming visualize operator that produces a custom bar or line chart of your query results, which can be saved for later reuse or to a dashboard!
To see how PantherFlow can accelerate your investigations and surface critical security insights, watch our webinar. We look at the what and why of PantherFlow, and we show you how to use it to investigate a threat scenario involving an account compromise, data exfiltration, and privilege escalation.







